
یکی از بزرگترین چالشهای دیجی کالا در مسیر پیشرفت، خودکار کردن فرایندهایی است که بهصورت دستی و توسط کارشناسها انجام میشود. برای مثال مدیریت نظرات کاربران یکی از آن فعالیتهایی است که در دیجیکالا توسط کارشناسها تیم محتوای شرکت انجام میشود. روزانه صدها نظر در پلتفرمهای مختلف دیجیکالا ثبت میشود که پیش از انتشار، باید آنها را بررسی کنیم. اما این بررسیها در یک فرایند کاملا دستی و به کمک نیروهای انسانی انجام میشود. به همین دلیل، با رشد سریع دیجیکالا و افزایش تعداد کاربران آن، محدودیتهایی برای واحدهای عملیات انسانی به ویژه واحد بررسی نظرات کاربران ایجاد شده است. محدودیتهای زمانی، هزینههای بالا و افزایش حجم کاری کارشناسها این واحد، فقط بخشی از چالشهایی است که با آن مواجه شدیم.
تا قبل از مهر ۱۳۹۹، تنها یک درصد از حجم نظرات کاربران توسط هوش مصنوعی بررسی میشد و بررسی ۹۹ درصد دیگر به عهده نیروهای انسانی بود که کاری سخت و زمانبر است. در حال حاضر دیگر نمیتوانیم حجم بالایی از نظرات را فقط به کمک کارشناسها، بررسی و منتشر کنیم. به همین دلیل در تیم AI دیجیکالا، تصمیم گرفتیم تا قابلیتهای هوش مصنوعی را بیشتر از قبل در فرایندهای انسانی وارد کرده و از قابلیت خودکارسازی فرایندها برای رفع محدودیتها و برطرف کردن چالشها استفاده کنیم.
در این مطلب از پشت پرده این تصمیم برایتان میگوییم و اینکه چطور توانستیم این چالش را به یک فرصت تبدیل کنیم.
چرا فرایندهای دستی مدیریت نظرات کاربران، دیگر کارایی لازم را نداشت؟
بالاتر گفتیم که با رشد دیجیکالا و افزایش تعداد کاربران، میزان نظرات هم با افزایش قابل توجهی روبهرو شد. در نمودار زیر شاهد رشد چشمگیر تعداد نظرات از بهمن ماه ۱۳۹۸ تا دی ماه ۱۳۹۹ هستیم که رشدی ۲ تا ۳ برابری را نشان میدهد.
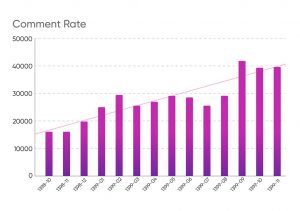
در این ماهها، نظرات ثبت شده در دیجیکالا از ۱۵ هزار عدد نظر ثبت شده به ۴۰ هزار عدد رسیده است! باید بگوییم که در حال حاضر یعنی در سال ۱۴۰۰، حتی این عدد به ۵۰ هزار هم نزدیک شده است. اینجا بود که فهمیدیم، کارشناسها واحد تیم محتوا دیگر نمیتوانند بهصورت دستی، این حجم از نظرات را مدیریت کنند. چون با همان سیستم قبلی باید شدت حدود ۳ برابر کار میکردند که این عملا غیر ممکن است!
از نظر ما، تنها راهکار برطرف کردن این چالش، خودکارسازی فرایندها به کمک هوش مصنوعی بود. اما قبل از اینکه، از خودکارسازی و استفاده از قابلیتهای هوش مصنوعی صحبت کنیم؛ بهتر است که اول نگاهی به سیستم قبلی داشته باشیم، سیستمی که ما به آن لقب «پیکان دهه ۷۰» دادهایم.
پیکان دهه ۷۰: نگاهی به سیستم مدیریت نظرات کاربران در دیجیکالا، قبل از توسعه قابلیتهای هوش مصنوعی
در مدل قبلی، ۹۹ درصد از نظرات توسط کارشناسها مدیریت میشد. بهاینترتیب که ۹۶ درصد آنها تایید و ۳ درصد آنها رد میشد. سهم هوش مصنوعی در مدیریت این نظرات، فقط یک درصد بود! یعنی فقط یک درصد از کل نظرات ثبت شده در دیجیکالا بهصورت خودکار رد میشدند.
برای درک بهتر این موضوع، نگاهی به نمودار زیر بکنید.
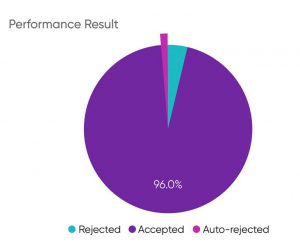
این مدل، یک شبکه عصبی عمیق بر پایه LSTM (فرهنگستان زبان فارسی: بلندواژه کوتاه حافظه) است. شاید در ظاهر مدل ناکارآمدی نباشد، اما در کاهش چالشها برای واحد مدیریت نظرات، خیلی هم موثر نبود. چون این مدل فقط میتوانست بخشی از نظرات را «رد» کند. یعنی قابلیت بررسی نظرات برای «تایید» آنها را نداشت!
جالب است بدانید که باتوجهبه به استانداردها و سیاستهای تیم محتوای دیجیکالا، فقط ۴ درصد از کل نظرات رد میشوند. پس این مدل فقط میتوانست روی ۴ درصد تاثیرگذار باشد که از این مقدار هم، طبق نمودار بالا، فقط یک درصد از نظرات را تشخیص داده و رد میکرد. به همین دلیل سهم چشمگیری در کاهش حجم کاری کارشناسان ایفا نمیکرد. پس به مدلی نیاز داشتیم که بتواند علاوه بر رد کردن نظرات، به تایید آنها هم بپردازد.
انتخاب مدلی با کمترین پیچیدگی: از BERT تا LSTM برای طراحی یک سیستم خودکار مدیریت نظرات کاربران
همیشه یکی از چالشهای مهم در پیادهسازی مدلهای مختلف به خصوص روی کلانداده (Big Data)، انتخاب مدلی با کمترین پیچیدگی است. به همین دلیل در طراحی سیستم جدید، به سراغ مدلهای سنگینتر مثل BERT نرفتیم و تلاش کردیم تا همان مدل قبلی بر پایه LSTM را بهبود داده و قابلیتهای جدیدی مثل فرایند تایید خودکار را به آن اضافه کنیم تا به یک مدل Real Time یه به اصطلاح بیدرنگ برسیم.
اما اضافه کردن فرایند تایید خودکار نظرات کاربران، کار سادهای نیست. چون میتواند هزینههای مستقیم و غیرمستقیم زیادی را به شرکت تحمیل کند. پس باید یک پسپردازش (Post-Processing) هم برای کاهش خطاهای احتمالی در نظر میگرفتیم که در ادامه، بیشتر از آن صحبت میکنیم.
نگاهی به ساختار کلی مدل
مرحله اول: انتخاب ویژگی
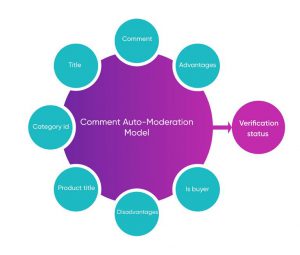
انتخاب ویژگی یا Feature Selection، همان فرایند انتخاب زیرمجموعهای از ویژگیهای مرتبط برای ساخت مدل است. ما در این فرایند، چند ویژگی مشخص را به عنوان ورودی مدل انتخاب کردیم که عبارتاند از:
- محتوای نظر
- نقاط ضعف و قوت نظر
- عنوان نظر
- گروه کالایی کالا
- عنوان کالا
- خریدار بودن یا نبودن شخصی که نظر را ثبت کرده
در نهایت خروجی، میزان احتمال تایید شدن نظر ورودی را تخمین میزند.
با پشت سر گذاشتن مرحله اول یعنی انتخاب ویژگی، به مرحله دوم میرسیم. مرحلهای که باید از پیشپردازش یا Preprocessing بیشتر بگوییم.
مرحله دوم: پیش پردازش
در مدلهای متنی معمولا یک مرحله پیشپردازش وجود دارد. پیشپردازشی که ما روی متنهای نظرات انجام میدهیم از دو بخش تشکیل شده است.
در بخش اول که به اصطلاح به آن Normalizer گفته میشود، سعی میکنیم از پیچیدگیهای اضافی ورودی کم کنیم. برای مثال اعداد انگلیسی به فارسی تبدیل میشود، علائم نگارشی از کلمات جدا میشود، «ی» عربی به فارسی تبدیل میشود و… .
اما بخش دوم یا Tokenizer، کمی مفصلتر است. در نظر بگیرید که هر ویژگی متنی توزیع جداگانهای دارد و یکی از ویژگیهای ما مثل «گروه کالایی محصول» هم متنی نیست. برای این مسئله به طور خلاصه، هر کدام از ویژگیهای متنی به یک Tokenizer و سپس Indexer وصل میشود که در فرایند Tokenizing، بخش Indexing درست میشود که این بخش هم به Embedding مدل وصل میشود.
اما سوالی که به وجود میآید، این است که ویژگی عنوان کالایی محصول یا همان Category ID را چگونه به مدل دهیم؟ همانطور که میدانید اولین راهحل برای ویژگیهای چند مقداری یا Categorical، استفاده از الگوریتم One-Hot Encoder است؛ اما در دیجیکالا تعداد همهی عنوانهای کالا بسیار زیاد است و این کار خیلی منطقی نیست.
راهحلی که ما استفاده کردیم این بود که به ویژگی «عنوان کالا» به عنوان یک متن نگاه کرده و به یک بردار ۶۴تایی نگاشت یا Mapping میکنیم؛ این بردار در طول فرایند یادگیری آموزش (Train) میبیند.
مرحله سوم: معماری مدل
ساختار مدل پیشنهادی را میتوانید در شکل زیر ببینید.
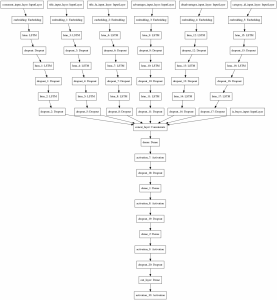
همانطور که در بلوک دیاگرام مدل قابل مشاهده است، هرکدام از بخشهای مبتنی بر متن ورودی، پس از گذر از لایه Embedding، وارد یک زیر شبکهی شامل سه لایه LSTM میشود. پس خروجی هر زیر شبکه LSTM در کنار هم قرار میگیرند و آخرین ورودی که خریدار بودن یا نبودن کاربر را تعیین میکند و تک نورون است هم در کنار سایر خروجیهای مختلف قرار میگیرد.
خروجی شبکه مقدار احتمال تایید شدن نظر ورودی است. برای تعیین وضعیت نظرات از روی خروجی شبکه، دو مقدار Threshold برای تایید و رد، در نظر گرفته شده است که نظراتی که احتمال تایید آنها بین این دو مقدار قرار میگیرد، به معنای عدم اطمینان مدل در تصمیمگیری هستند و برای بررسی بیشتر برای کارشناسها ارسال میشوند.
مرحله چهارم: پس پردازش
در مرحله پسپردازش به دنبال کاهش مثبتهای کاذب یا False Positive هستیم. در واقع در این مرحله، میخواهیم نظرات نامناسبی که به هیچ وجه نباید تایید شوند را مشخص کنیم. برای این کار از Tokenizer یک مدل BERT استفاده کردیم تا ریشه عبارتهای نامناسب را پیدا کنیم. سپس این نظرات در چند فهرست قرار میگیرند که این فهرستها شامل کلمات نامناسب و سایر عبارتهای غیرقابل انتشار هستند. سپس این کلمات بررسی شده و اگر تایید شوند، مدل تایید نهایی را ارایه میدهد.
برای مثال در کلمه «نشستندی»، توکنایزر این کلمه را به صورت «نشست + ندی» تقسیم میکند و اگر کلمه «نشست» در فهرست سیاه باشد، تمام مشتقات این کلمه را تا حد خوبی شناسایی کرده و نظراتی که دارای این مشتقات هستند را مستقیما برای کارشناس ارسال میکند.
مرحله پنجم: شناسایی تولیدکنندگان نظرات نامناسب
یکی از مشکلاتی که ما در بخش نظرات با آن روبهرو هستیم، این است که بعضی کاربران به دلایل مختلف مثل دریافت امتیاز دیجیکلاب، تخریب کالای رقیب و.. به تولید تعداد زیادی نظر میپردازند. برای حل این مشکل معیاری به عنوان Spammer بودن تعریف میکنیم.
معیاری که توسط آن، احتمال Spammer بودن هر کاربر مشخص میشود، به صورت زیر تعریف شده است:
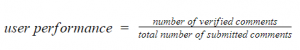
پس مقدار بازدهی هر کاربر در بازه زمانی مشخصی محاسبه شده و باتوجهبه نمودار زیر، وضعیت Spammer بودن آن تعیین میشود.
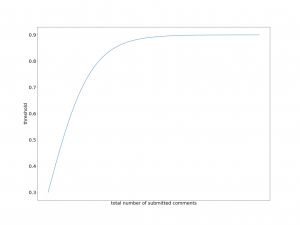
نمودار بالا مقدار Threshold برای تصمیمگیری در مورد Spammer بودن هر کاربر را تعیین میکند. مقدار این Threshold به صورت داینامیک و باتوجهبه تعداد کل نظرات ثبت شده توسط هر کاربر در بازه زمانی مورد نظر به دست میآید.
طبق نمودار، هرچه تعداد کل نظرات ثبت شده توسط کاربر بیشتر باشد، بازدهی مورد انتظار از آن کاربر هم بیشتر میشود. در نهایت اگر مقدار بازدهی کاربر مورد نظر کمتر از Threshold آن کاربر باشد، به عنوان Spammer شناسایی شده و برای کارشناس به منظور بررسی دقیقتر فرستاده میشود.
غیر خطی بودن این نمودار به این دلیل است که با تعداد نظرات کم، Threshold بالاتری در نظر گرفته شود و شناسایی کمتری انجام شود.
مرحله ششم: نتایج مدل
نتایج مدل پیشنهادی را میتوانید در جدول زیر ببینید. همانطور که در بخش قبل توضیح داده شد، بخشی از نظرات ورودی که مدل نسبت به آنها اطمینان ندارد، تایید یا رد نمیشوند و مستقیما برای کارشناس ارسال میشود. به دلیل عدم توازن (Imbalance) در دادگان، Accuracy به تنهایی معیار مناسبی برای ارزیابی مدل نخواهد بود. به همین دلیل معیارهای Precision ،Recall و F1 برای ارزیابی مدل محاسبه شده است.
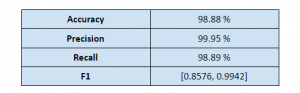
در این مدل، تعداد مثبتهای کاذب یا False Positive، اهمیت زیادی دارد. یعنی انتشار نظراتی که نباید منتشر شوند، به مراتب ریسک بیشتری نسبت به منتشر نکردن نظرات مثبت دارد. پس پارامترها طوری تنظیم شدهاند که نتایج، کمترین ریسک را در صورت امکان داشته باشد. مقدار Precision بالا نشان دهنده موفقیت نسبی در کم کردن تعداد False Positive است.
کلام آخر: تاثیر و سهم مدل
در نهایت این مدل باتوجهبه انجام همزمان تایید و رد خودکار نظرات کاربران توانست حجم قابل توجهی از نظرات را به صورت خودکار بررسی و نیاز به نیروی انسانی را کمتر کند.
نمودار زیر، تاثیر و سهم مدل پیشنهادی روی نظرات ثبت شده روزانه را نشان میدهد. طبق نمودار، حدود ۷۷ درصد از نظرات توسط این سیستم و به کمک هوش مصنوعی تایید شده و حدود ۲ درصد رد شدهاند. ۲۱ درصد باقیمانده هم برای کارشناسها جهت بررسی ارسال شده است. این ۲۱ درصد همان بخشی از نظرات است که مدل در مورد آنها اطمینان کافی ندارد. در نتیجه سهم بررسی خودکار (تایید خودکار + رد خودکار) برابر ۷۹ درصد است.
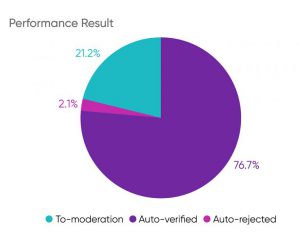
در روزهای گذشته در سال ۱۴۰۰، روزانه تعداد ۴۱ هزار نظر در دیجیکالا ثبت شده است که برای بررسی این تعداد نظر نیاز به ۱۳/۵ کارشناس است. اما با استفاده از سیستم بررسی خودکار نظرات و بررسی حدود ۷۹ درصد توسط این سیستم، تنها به ۳/۵ کارشناس جهت بررسی نظرات باقیمانده نیاز داریم. در نتیجه سایر کارشناسها به بررسی مواردی میپردازند که توسط ماشین قابل انجام نیست و این یعنی استفاده از هوش مصنوعی برای صرفهجویی در زمان ارزشمند منابع انسانی و بهبود عملکرد آنها با هدفمندتر کردن فعالیتهایشان.
در آینده تلاش میکنیم تا میزان درصد بررسی خودکار نظرات کاربران را بالاتر برده و در نهایت تمامی نظرات توسط این سیستم تایید شوند.